See the screen shots below.
(Download the Collocate demo. The demo processes data in the same manner as the full version, but the results are limited to the top 5 items. The zip file includes the Collocate manual.)
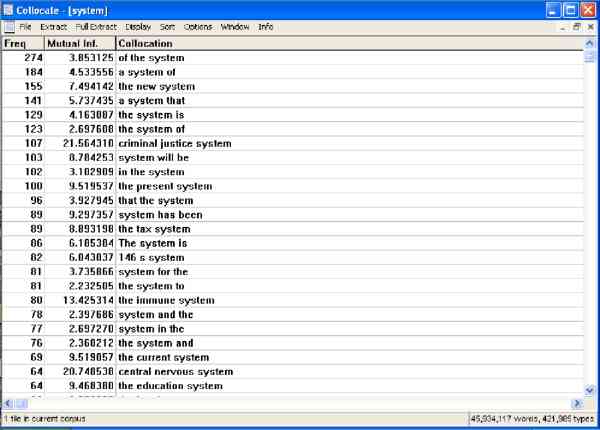
In the following screen shot the results are shown of a search for system (with a span of 3) in a 46-million word corpus. The three-word phrases are ordered by Mutual Information score.

The raw frequency ordering is shown below.
Collocate 1.0 allows the user to find collocates, collocations and n-grams in a corpus in several different ways. The Extract command allows the user to enter a word (or phrase) and specify a span (e.g., 2 words), as shown above. The results for a span of 2 words can be ordered by frequency or by statistical score (Mutual Information, t-score, or log-likelihood) or by alphabetical order or by POS tag, etc.
A span of up to 12 words is allowed, but the only statistical score in spans larger than 2 is Mutual Information.
The search string can be based on or include part-of-speech tags, assuming that the corpus is tagged. In addition, the search for words may be specified using the powerful regular expression syntax.
The Full Extract command processes the whole corpus according to the specified parameters and produces a list of collocations. There are two basic commands. An n-gram command creates a bigram (trigram, n-gram) list for the corpus, along the lines of a simple word frequency list.
A 5-gram list is shown below

The Extract command produces a list of collocations which are identified using the cost criterion of Kita et al or Mutual Information, as shown in the screen shot of the dialogue box.

The results can be saved to a file or printed out.
Educational Price. Single user: $45
Site licence (2-year, 15 users) $395